- Published on
Understanding Text Embeddings - The What and How of Embedding Models!
- Authors

- Name
- Juan Angel Suarez
- @j_ange1_
Have you ever wondered how your smartphone understands your questions or how search engines seem to read your mind? The answer lies within text embeddings.
Whether you're a budding data scientist, a seasoned software engineer, or somewhere in between, understanding text embeddings can fundamentally level up your approach to text data. As a software engineer who loves to explore, I find text embeddings particularly cool and immensely powerful. Today, I’m going to break down what text embeddings are, how they work, and show you some real-world applications where they shine. Ready? Let's dive in!
What Are Text Embeddings?
At its core, a text embedding is a technique for representing text in a form that computers can understand (think numbers, not letters) and process efficiently. Why is this needed, you ask? Well, while humans excel at understanding written content, computers do not—they need numbers. Embeddings convert text into a dense vector of floating-point values where similar text results in similar numerical values. This magic lets us perform all sorts of machine learning wizardry on natural language.
How Do Text Embeddings Work?
Imagine trying to understand the relationship between words without reading them but by looking at numbers instead. Text embeddings allow exactly that by capturing semantic meaning and relationships in a dense vector space.
Real-World Applications of Text Embeddings:
- Search Engines: Improve the relevance of search results by understanding the query and content in the same vector space.
- Recommendation Systems: Suggest relevant articles or products by finding similarity between the users' text inputs and available options.
- Sentiment Analysis: Determine the sentiment expressed in texts by training classifiers using vectorized forms of text.
Challenges in Using Text Embeddings
While text embeddings have revolutionized how machines understand human language, their use is not without challenges. These challenges not only affect the performance of machine learning models but also raise important ethical considerations. Here, we will explore three main challenges: dimensionality, contextuality, and bias.
Dimensionality
One of the inherent challenges in using text embeddings is dealing with high-dimensional data. Text data is naturally sparse and typically requires a large dimension space to be represented effectively as embeddings. High dimensionality can lead to several problems:
- Computational Complexity: The more dimensions an embedding has, the more computational resources are required to process data. This can make training models slower and more expensive.
- Curse of Dimensionality: In high-dimensional spaces, the volume of the space increases so much that the available data become sparse. This sparsity is problematic for methods requiring statistical significance, as the data needed often grows exponentially with dimensionality.
- Overfitting: With too many dimensions, models can become overly complex. This complexity can lead to overfitting, where a model learns details and noise in the training data to an extent that it negatively impacts the performance of the model on new data.
Techniques such as dimensionality reduction (e.g., PCA, t-SNE) or using more sophisticated embedding methods (like those generated by deep learning models that inherently manage dimensionality) are commonly employed to mitigate these issues.
Contextuality
The meaning of words can change based on the context in which they are used, a property known as polysemy. Traditional embedding techniques like Word2Vec or GloVe assign a single vector to each word, ignoring the different meanings that word can have in different contexts. For instance, the word "bank" can refer to the edge of a river or a financial institution depending on the sentence in which it is used.
This limitation can be addressed by context-aware embeddings like BERT or ELMo, which generate embeddings for words based on the other words in the sentence. Thus, the word "bank" would have different embeddings in "He sat on the bank of the river" versus "He deposited money in the bank," allowing models to better capture and utilize the nuances of language.
Bias
Text embeddings can inadvertently encode and perpetuate biases present in the training data. Since embeddings learn from existing text data, any biases — gender, race, age, etc. — in that data can be reflected in the model's behavior. For example, embeddings might associate certain professions more closely with one gender than another.
The ethical implications are significant, as biased models can lead to unfair or prejudiced outcomes when used in applications like hiring tools, search engines, or recommendation systems. Addressing this issue involves techniques such as bias identification and mitigation in embedding models, or using more balanced and representative training data.
Embedding Models In Action
Word2Vec: Mastering Word-Level Semantics
Introduced by Google in 2013, Word2Vec is an effective model that focuses on individual words, creating dense vector representations. It excels at capturing semantic and syntactic relationships between words, which is ideal for:
- Finding similar words and word associations.
- Solving analogies.
- Boosting algorithms that rely on local context understanding.
In the following examples I will show you how you can leverage text embeddings to do the following:
- Initialize and train a Word2Vec model
- View embeddings per word
- Find semantically related words
- Compute the similarity (distance) between two words
Here’s how you can implement Word2Vec with Python:
from gensim.models import Word2Vec
# Example sentences
sentences = [
["data", "science", "is", "fun"],
["machine", "learning", "is", "awesome"],
["machine", "learning", "is", "fun"],
["deep", "learning", "is", "a", "subfield", "of", "machine", "learning"],
["nlp", "is", "a", "subfield", "of", "artificial", "intelligence"],
["the", "king", "rules", "his", "kingdom"],
["the", "queen", "rules", "her", "kingdom"],
["a", "prince", "is", "a", "young", "king"],
["a", "princess", "is", "a", "young", "queen"],
["man", "works", "woman", "works"],
["he", "is", "strong", "she", "is", "strong"],
["his", "robe", "her", "robe"]
]
# Initialize and train a Word2Vec model
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
print('Keys in the model: ', list(model.wv.key_to_index))
Output: Keys in the model: ['is', 'a', 'learning', 'machine', 'robe', 'kingdom', 'fun', 'subfield', 'of', 'the', 'rules', 'his', 'king', 'queen', 'strong', 'works', 'young', 'her', 'deep', 'science', 'he', 'woman', 'awesome', 'man', 'princess', 'nlp', 'artificial', 'intelligence', 'prince', 'she', 'data']
# View embeddings per word
vector = model.wv['data']
print("Vector for 'data':", vector)
Output: Vector for 'data': [ 1.9567307e-04 2.1450371e-03 1.0661827e-03 7.5868950e-03 -4.4239080e-03 3.2462235e-04 7.0073190e-03 2.2519126e-03 4.2423336e-03 4.3023555e-03 -1.2654875e-03 -8.3232336e-03 3.0464542e-03 -8.8727642e-03 -2.6619213e-03 -9.3912166e-03 -4.5982251e-04 -7.8640850e-03 7.4140881e-03 -4.8920400e-03 9.9181971e-03 -9.0323491e-03 -4.3113311e-03 1.9295603e-03 -2.9979011e-03 1.4454976e-03 -3.6821587e-03 -8.9377171e-04 -5.7267612e-03 -9.8195998e-03 6.3404068e-03 3.8450040e-04 6.5115197e-03 -7.4731335e-03 3.6630007e-03 -9.8976009e-03 7.6108286e-03 5.9237545e-03 -6.1183707e-03 8.2128029e-03 -5.5806260e-03 -8.5524227e-03 1.5001835e-03 3.1793686e-03 -8.0969986e-03 -8.9354431e-03 9.1706691e-03 1.6427538e-03 8.7405730e-04 2.4796545e-03 -3.5082651e-03 1.7351022e-03 1.9570177e-03 9.8059075e-03 -5.6075305e-03 2.2727838e-03 6.3064215e-03 -6.6768136e-03 -8.9333514e-03 8.6579872e-03 6.8378402e-03 -4.0211603e-03 5.7423692e-03 7.8941189e-04 -5.0125415e-03 -1.3499081e-03 -4.9002348e-03 6.1333720e-03 1.9625274e-03 -8.3197402e-03 -1.4520562e-04 -2.6476916e-03 6.6075521e-03 -1.1449042e-03 7.6661739e-03 1.9482464e-03 -3.8298622e-03 8.1573073e-03 2.9485817e-03 -3.9692018e-03 -5.5998899e-03 -3.0891474e-03 -5.1349374e-03 3.4424877e-03 -9.2841340e-03 -5.8215777e-03 3.3417069e-03 1.9830732e-04 5.9961271e-03 -3.6051942e-03 -5.1566685e-06 2.4753429e-03 5.4595289e-03 1.6111167e-03 9.8155262e-03 3.7172353e-03 -7.1821022e-03 -1.4075302e-03 -8.3660297e-03 -5.3271358e-03]
# Find semantically related words
print("Similar words to 'science':", model.wv.most_similar('science'))
Output: Similar words to 'science': [('subfield', 0.31906771659851074), ('prince', 0.18881569802761078), ('strong', 0.16199900209903717), ('nlp', 0.12767480313777924), ('fun', 0.1107269674539566), ('artificial', 0.11028187721967697), ('his', 0.09723721444606781), ('of', 0.09672992676496506), ('rules', 0.08644552528858185), ('woman', 0.05719584971666336)]
# Compute the similarity between two words
similarity = model.wv.similarity('machine', 'learning')
print("Similarity between 'machine' and 'learning':", similarity)
Output: Similarity between 'machine' and 'learning': -0.013523996
OpenAI's Ada: Unleashing Document-Level Insights
On the flip side, OpenAI’s Ada model text-embedding-ada-002 provides embeddings that encapsulate the semantic meaning of entire text sequences or documents. It is more suited for:
- Semantic search across large documents.
- Clustering and similarity measurement at sentence or document levels.
- Integrating contextual nuances over longer stretches of text.
Ada's embeddings are accessible via OpenAI’s API, offering ease of use and integration into larger systems without the need for extensive local setup.
Here's a quick example of using OpenAI's API to generate embeddings with Ada and their different use cases:
pip install openai
import openai
from scipy.spatial.distance import cosine
# Your OpenAI API key
openai.api_key = 'your-api-key-here'
# Text for which you want to generate embeddings
text = "Machine learning is fascinating."
# Generate embeddings
response = openAiClient.embeddings.create(
model="text-embedding-ada-002",
input=text
).data[0].embedding
# Print the embedding vector
embedding_vector = response
print("Embedding vector:", embedding_vector)
Output: Embedding vector:
[-0.026519114151597023, 0.008567114360630512, 0.016965482383966446,
-0.016705874353647232, 0.00041010192944668233, 0.0152910016477108, -0.0001406556402798742,
0.005863930098712444, -0.0133439302444458, -0.040654852986335754, 0.007684442214667797,
0.029102228581905365, -0.011202150955796242,
...,
-0.025740284472703934, -0.017951998859643936,
-0.006564876064658165, 0.010533656924962997, -0.015342923812568188, -0.023157170042395592,
-0.012188667431473732]
Calculate Cosine Similarity
import numpy as np
from scipy.spatial.distance import cosine
def get_embedding(text):
response = openAiClient.embeddings.create(
model="text-embedding-ada-002",
input=text
).data[0].embedding
return response
# Define a list of text pairs
text_pairs = [
("Artificial intelligence will transform many industries.", "AI is set to revolutionize the world."),
("Quantum computing will change the future of computing.", "AI is set to revolutionize the world."),
("Quantum computing will change the future of computing.", "Healthy dietary habits can improve life expectancy."),
("Renewable energy is crucial for sustainable development.", "Renewable energy is crucial for sustainable development."),
("We should invest more in fossil fuels to boost the economy.", "Renewable energy is crucial for sustainable development.")
]
"""
EXPLANATION
1. Highly Related Texts Expected Outcome: These two texts are very closely related as
both discuss the impact of artificial intelligence on a broad scale.
Therefore, the cosine similarity should be high, indicating a strong similarity.
2. Moderately Related Texts Expected Outcome: These texts are related through the theme
of future technologies affecting the world, but they focus on different technologies
(quantum computing vs. AI). The cosine similarity should be moderate, reflecting the
thematic but distinct technological focus.
3. Unrelated Texts Expected Outcome: These texts discuss completely different subjects—one
is about technology and the other about health. The cosine similarity should be low,
showing little to no relation between the content of the texts.
4. Identical Text Expected Outcome: Since the texts are identical, the cosine similarity
should be 1, indicating that the texts are exactly the same.
5. Text With Opposing Ideas Expected Outcome: These texts present opposing ideas regarding
energy sources and policy. The cosine similarity could still be moderate if the embeddings
capture the context of energy and policy discussions, but it should reflect the ideological differences.
"""
# Compute and print cosine similarities
for text1, text2 in text_pairs:
embedding1 = get_embedding(text1)
embedding2 = get_embedding(text2)
similarity = 1 - cosine(embedding1, embedding2)
print(f"Similarity between:\n'{text1}'\nand\n'{text2}'\nis: {similarity}\n")
Similarity Between
Output 1 'Artificial intelligence will transform many industries.' and 'AI is set to revolutionize the world.' is: 0.9123447114864355
Output 2 'Quantum computing will change the future of computing.' and 'AI is set to revolutionize the world.' is: 0.8402659811655547
Output 3 'Quantum computing will change the future of computing.' and 'Healthy dietary habits can improve life expectancy.' is: 0.722549468907339
Output 4 'Renewable energy is crucial for sustainable development.' and 'Renewable energy is crucial for sustainable development.' is: 1
Output 5: 'We should invest more in fossil fuels to boost the economy.' and 'Renewable energy is crucial for sustainable development.' is: 0.833985334996716
Semantic Search
def semantic_search(query, documents):
"""
Perform semantic search by calculating cosine similarities between query and document embeddings.
Parameters:
query (str): The query string for which to find relevant documents.
documents (list of str): A list of document strings to search within.
Returns:
list of tuples: Sorted list of documents with their similarity scores, highest first.
"""
# Get embedding for the query
query_embedding = get_embedding(query)
# Get embeddings for documents
doc_embeddings = [get_embedding(doc) for doc in documents]
# Calculate similarities
similarities = [1 - cosine(query_embedding, doc_emb) for doc_emb in doc_embeddings]
# Sort documents by similarity
sorted_documents = sorted(zip(documents, similarities), key=lambda x: x[1], reverse=True)
return sorted_documents
# Example usage
documents = [
"Climate change is affecting Earth.",
"Quantum computing will change the future of computing.",
"Renewable energy sources are key to sustainable development.",
"Fossil fuels still power much of the world.",
"The impact of technology on society is growing."
]
query = "technological advancements in energy"
# Perform semantic search
results = semantic_search(query, documents)
# Print results
print("Documents sorted by relevance to the query:")
for doc, sim in results:
print(f"Document: {doc}\nSimilarity Score: {sim:.3f}\n")
Here's how the output of the script might look. This technique is used to find other text that is semantically closely related to your a search query. In this case the search query is technological advancements in energy
| Document | Similarity Score |
|---|---|
| Renewable energy sources are key to sustainable development. | 0.847 |
| The impact of technology on society is growing. | 0.834 |
| Fossil fuels still power much of the world. | 0.821 |
| Quantum computing will change the future of computing. | 0.797 |
| Climate change is affecting Earth. | 0.775 |
Description of the Output:
Document 1: Renewable energy sources are key to sustainable development.
Similarity Score: 0.847
Explanation: This document directly addresses "technological advancements in energy" by discussing "renewable energy sources," which are a crucial and highly relevant part of energy advancements today. The focus on sustainable development links closely with current and future energy technologies, making this document highly relevant to the query.
Document 2: The impact of technology on society is growing.
Similarity Score: 0.834
Explanation: While this document does not specifically mention "energy," it discusses the broader impact of "technology on society," which implicitly includes technological advancements in various sectors, including energy. The high relevance score can be attributed to the general overlap in the theme of technology’s influence, which likely includes advancements in energy technology.
Document 3: Fossil fuels still power much of the world.
Similarity Score: 0.821
Explanation: This document is relevant as it discusses the current state of energy sources ("fossil fuels"), which are the traditional counterparts to newer, technologically advanced energy solutions like renewable energy. The discussion implies the need for and possibly the transition towards more advanced energy solutions, thus its relevance to the query about energy advancements.
Document 4: Quantum computing will change the future of computing.
Similarity Score: 0.797
Explanation: Quantum computing, while a technological advancement, is less directly related to the query focused on "energy" advancements. However, its potential applications in solving complex problems including those in energy sectors (like optimizing energy distribution or modeling molecular energy processes) might contribute to its relevance score.
Document 5: Climate change is affecting Earth.
Similarity Score: 0.775
Explanation: This document focuses on "climate change," which is an issue closely linked with energy usage and the need for new energy technologies that are more environmentally friendly. The relevance here stems from the indirect connection between technological advancements in energy (especially renewable sources) aimed at mitigating the effects of climate change.
Visualizing Text Embeddings:
Here are two graphs showing how different words cluster together in vector space:
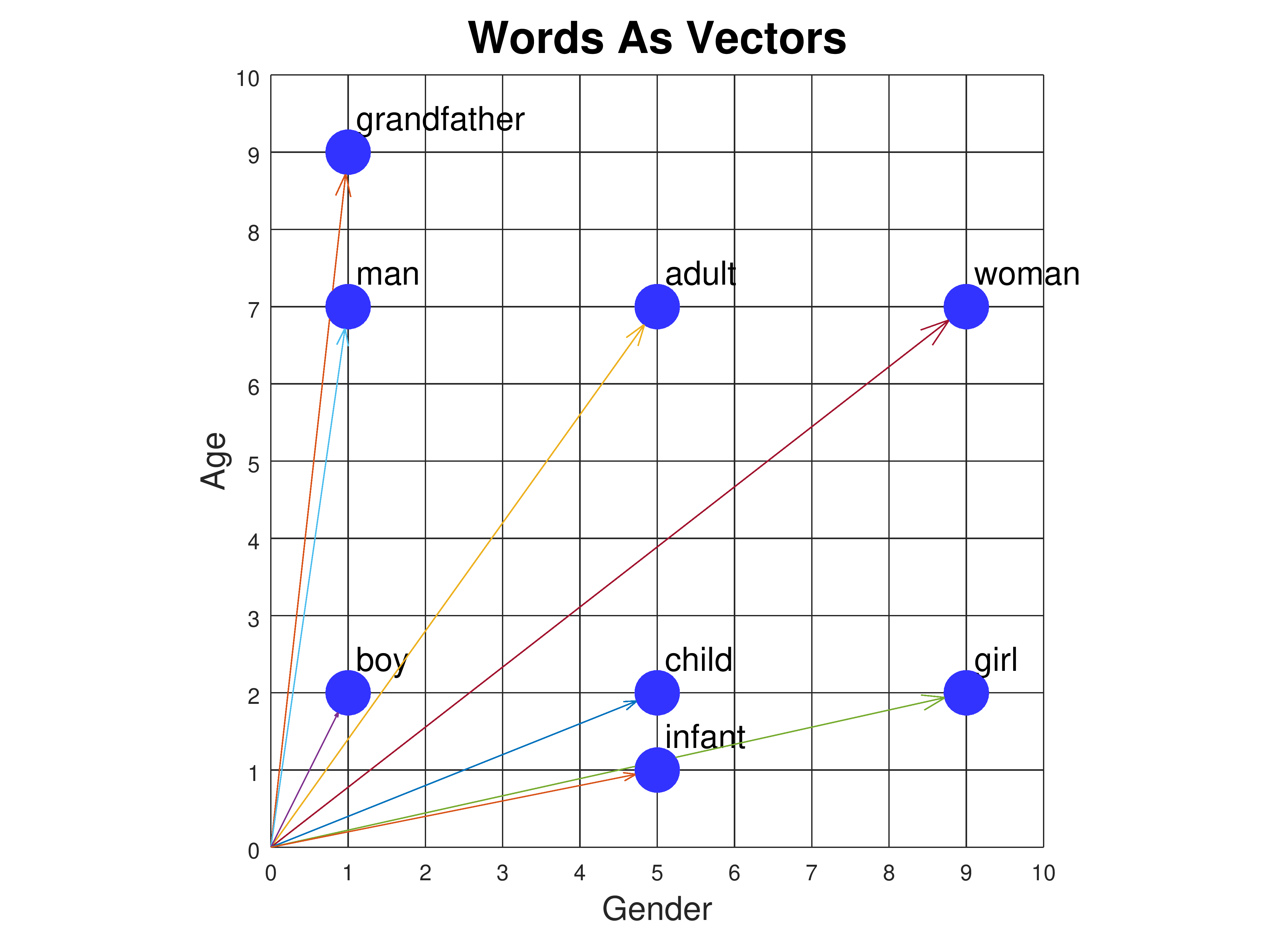 Figure 1: Source: CMU.
Figure 1: Source: CMU.
The closer two words are in this space, the more similar they are in terms of meaning. Here is another example.  Figure 2: Source: arxiv.
Figure 2: Source: arxiv.
Conclusion:
Text embeddings are a cornerstone of modern NLP applications. They transform the tricky task of understanding natural language into a high-dimensional, yet efficient, numerical task that machines handle like a champ. With the exponential growth of data, mastering text embeddings will not only enhance your projects but also place you at the cutting edge of AI-driven technologies.
Whether you’re tweaking a personal project or working at a startup, I encourage you to experiment with these models and explore the nuances they bring to the table.
Engage with Me:
Got questions, or want to share how you’ve used text embeddings in your projects? Drop a comment below or shoot me a message on LinkedIn. Let's keep the conversation going!